To make the software ready for the world market, English works pretty well for many markets, however when it comes to countries like France (where English is not really adored), or Thailand (where British never ruled) or many parts of the world where English is understood only at a rudimentary level, the software in local language can be successful.
Globalization is the ability to handle data in multiple languages and with local conventions, while Localization is the ability to manifest the user interface in the local languages.
1 Globalization
To be able to handle data in any language or many languages, the software should be Unicode compliant. Newer languages like C#, Java, Python, JavaScript are already Unicode compliant. C/C++ code needs efforts to ensure that it is Unicode compliant.
1.1 Unicode
One should make an effort to understand the basics of Unicode. One can refer to Unicode.org or (for a simplistic version) my article: https://bit.ly/3sxUng7 .
1.2 Data Persistence
To be able to persist data in any language or many languages, the data must be stored in any Unicode compliant encoding. Common choices are UTF-8 (where ASCII remains 1 byte, and endian-ness does not matter) and UTF-16 (where all characters are at least encoded as 2 bytes, and endian-ness matters). In case most of the data is ASCII based, it is convenient and easy to use UTF-8. UTF-8 creates a significant in increase in size when characters beyond the ASCII range are used e.g., French character ‘ç’ is represented in 2 bytes \xc3\xa7, Hebrew character ‘ש’ is represented as \xd7\xa9, Devanagari character ‘ॐ’ is represented in 3 bytes \xe0\xa5\x90, and Japanese character ‘聞’ is represented in 3 bytes \xe8\x81\x9e, and so on. In spite of the increase in size, UTF-8 remains the widely used character encoding, possibly because the universal acceptance, availability of cheap storage and high speeds of networks.
1.3 Sending/Receiving Data
Though not directly connected with Globalization, to be able to successfully send/receive/transport data across machines there are two ways
1.3.1 Transporting persisted data
A persisted version of data (saved file) is sent and received. The sender and the receiver must conform to the format agreed upon. If a file containing textual matter is stored in UTF-8 and if both the receiver and sender know that the data is UTF-8 encoded, it will be interpreted correctly.
1.3.2 Transporting ephemeral data
This typically happens during client-server communication, or when devices send data to peers or servers. The sender-receiver protocols should be agreed upon either in advance or dynamically. As an example, in SOAP/REST API interaction, the data is sent in XML/JSON/Base64 encoded formats or LZCompressed+Base64 encoded format, and the HTML header can contain the information about the format used. The default encoding in HTML5 is UTF-8. See this article https://webhint.io/docs/user-guide/hints/hint-meta-charset-utf-8/. In case of binary data transfers using custom ports, care should be taken to understand and appropriately interpret the Endian-ness / floating point representation of the data being sent.
1.4 Date and Time storage
1.4.1 Date and Time Formats
This is the part where the software needs to worry about the way data is represented locally. Misinterpretation of Date stamps and Time stamps can lead to serious problems.
e.g.
If the date entered by a user is 6/11/12, it is open to interpretation. In USA people will think it is 11th June 2012, in Europe/India it will be thought of as 6th November 2012, and in Japan, it will be considered to be 12th November 2006. Therefore, it is important to send the date format (d/M/yy etc.) with the date if the date is coming in as a text string, or always use a standard format yyyy-MM-dd.
It also matters where the date was intended for. If a bank transaction happens at 0900 HRS in Mumbai on 12/January/2022, it is still 11/January/2022 is Seattle/San Francisco. This brings us to the consideration of Time Stamps. It makes sense to record not just the date but also the time and time zone with the date.
One can convert a datetime stamp to number of milliseconds (or any other measure of time) from a known epoch point and place to eliminate the ambiguity. Please refer to https://en.wikipedia.org/wiki/Epoch_(computing). Java Date is internally a long number which is the number of milliseconds passed since passed since 1st January 1970 at 00:00:00 HRS UTC. UTC is the Universal Time Coordinated. Similarly in .NET, it is counted starting at 1st January 0001 at 00:00:00 HRS UTC and in 100 nanosecond intervals.
It is important to store Date as a Date Time stamp using one of the conventions. A good practice is to store everything UTC on the server and convert to the value in the appropriate time zone for display and calculations. If the time stamps are stored in SQL Servers, most of the SQL servers record time stamps accurately, in the servers’ time setting.
Even if the software is not intended to be used internationally, the system may need to keep the time zone information, because many countries have multiple time zones. Keeping the Date and Time in UTC helps.
Some countries follow daylight savings time adjustment. Therefore, if the software is counting time difference from 5 November 2022 at 0900HRS to 6 November 2022 at 0900 HRS, in USA, it would be 25 hours, because on 6 November 2022, the clocks will turn back 1 hour at 0200 hrs. The operating systems handle this fine and if the software maintains the Date Time stamps in UTC, it then becomes just a matter of adding or subtracting difference between UTC and the target time zone.
Different countries require different Date and Time formats. The software should never store the formatted text for Dates and Time. The order of Year, Month, Days is different and month names are also different.
e.g., to store 12th August 2022, one can use 2022/08/12, 8/12/22, 8/12/2022, 12/8/22, 12/8/2022, 2022-August-12, 2022-août-12 (French), २०२२-अगस्त-१२ (Hindi), etc. Similar to the dates, time can be represented in multiple ways, 24 hours format, 12 hours format with AM/PM suffix. There are many ways to write say 6:30 in the evening: 6:30 PM, 1830 HRS, 18h30 etc.
One must remember never to store the date and time information is formatted strings, but format it to the desired setting of the target prior to display/printing.
1.4.2 Calendars
It is common for governments and official documents to use the official calendar of the country. E.g., Official calendar of Thailand is the Buddhist Calendar, or Official calendar of India is the Indian National Calendar, both have constant day offsets from the Gregorian calendar, and Saudi Arabian government uses the official Hijri Calendar, which is a lunar calendar, and Israel government uses the Hebrew Calendar (which is similar to the Hindu Lunar Calendar). It makes sense for the software to convert to standard Gregorian dates in UTC for storing and convert back for display/printing.
1.4.3 Money and Numbers
Typically, in USA, the money amount 123456.78 is displayed as “$123,456.78”. In France, however it will be displayed as “123 456,89 €”. In India, “₹ 1,23,456.89” will be the appropriate format. In some countries like South Korea e.g., the amounts in jeon (1/100 of a Won) are never used in normal transactions and amounts are just written as ₩ 123.
One needs to remember that whatever is displayed, frequently comes back and the software needs to parse it back. One has to use the appropriate format. In USA, UK, India, the Decimal Separator is the ‘.’ (dot) but it is ‘,’ (comma) in France or other parts of Europe.
It is important to store the currency of transaction, though generally not too many transactions happen in normal users’ account in different currencies, and even if a US person does a transaction in Canada, the amount is converted by the bank to USD by the financial institution. However, if the software is for financial institutions dealing in multiple currencies, one must (obviously!) record the currency.
1.4.4 Names of countries
There are a few cases where some country / region names are unacceptable in some countries, e.g., the China – Taiwan issue. One should avoid referring to Taiwan as R.O.C. in mainland China (P.R.C.).
1.4.5 Display Direction
This matters in the languages or countries where the culturally correct look and feel is Right-To-Left, i.e., most of the countries in the middle east.
1.4.5.1 Desktop and Mobile Applications
Underlying operating systems like Windows, Linux, iOS, Android have support for right-to-left display and text. One should try and leverage these features of the operating systems. Here is a screenshot of Hebrew localized version of Microsoft Excel.
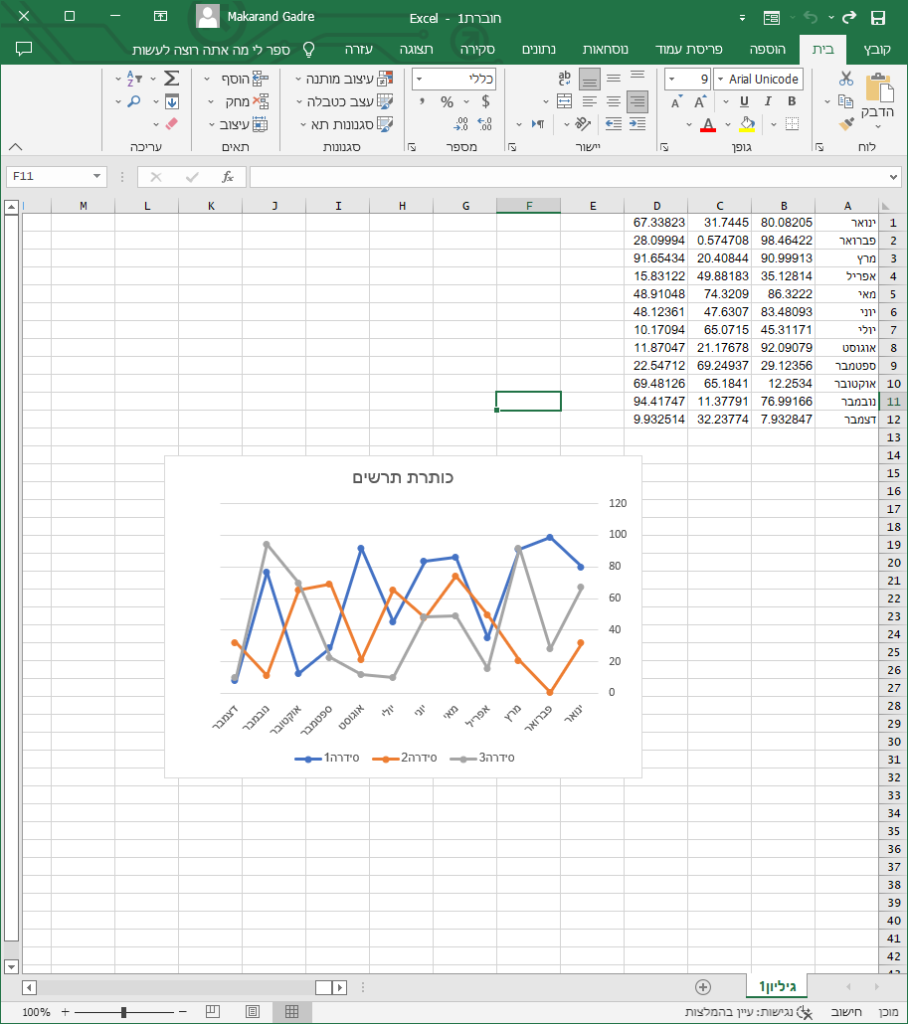
1.4.5.1 Web pages
HTML works fine generally if the proper tag (dir="rtl") is placed in the appropriate elements and all the elements tagged correctly will flow Right-To-Left. One can visit the web sites of Arabic / Hebrew / Urdu newspapers e.g., https://www.aleqt.com/ and study the use of this HTML tag.
1.4.6 Text Display
Display of text of many (almost all) Unicode Scripts is generally well handled by standard controls in HTML, Windows, iOS, Linux, and Android. Writing a language compliant editor even without the bells and whistles like spelling checker and grammar checker, is a monumental task and there are major software companies who have invested immense efforts in these. Here are a few interesting text rendering complexities apart from the Right to Left text flow.
- Shape Shifters: Characters that change shape depending upon what is before and after the character. This is always so for Arabic script and many Indic scripts like Devanagari.
- Ligatures: Two or more characters form a singles shape on the screen. This is font dependent too. Latin script also has some ligatures which are mostly used in culturally correct and aesthetic representation of text. Please refer to https://en.wikipedia.org/wiki/Ligature_(writing).
- Kashida justification: In Arabic scripts some characters are connected horizontally by a ghost “kashida” character during display for calligraphic purposes. Please refer to https://en.wikipedia.org/wiki/Kashida.
- No space between words: Thai script generally does not use spaces between words. A comparative example in English would be the two sentences:” There was a handout for me”, and “There was a hand out for me”. In Thai both would look like therewasahandoutforme, and the code in edit controls use complex dictionary and grammar rules to figure out the word-breaks.
- Vertical Writing: Traditional Japanese, Mongolian scripts are written top-to-bottom and paragraphs flow Right-To-Left in Japanese and Left to Right in Mongolian.
In general, the best bet is to use standard well known controls to display text.
2 Localization
One should think about the target audience and decide the languages / countries to localize for. This can open a can of worms. Please refer to the languages specified in ISO-639. In USA, one may want to support Spanish (Mexican). In Canada one may be forced to support French (Canada). When it comes to the European Union or India, there are many that one can decide to support but one must remember that English (United States) is different from English (Great Britain) for spellings (color v/s colour).
Localization has three important things to worry about. Images, Colors and Text.
2.1 Images
One must be very cautious about creating images / logos / clip arts depending upon the target consumer. Images that seem to be perfectly fine in one culture may be offensive in other. Take the example of the Thumbs Up sign. It signifies a positive emotion like “Yes / I Agree / Good job / Ready to go” to Americans, Indians, Britons but it suggests an expletive in Greece, Russia, Middle East, Latin America similar to what the middle finger means to Americans. See https://www.deseret.com/2011/4/15/20371322/international-business-international-symbol-icon-blunders-can-be-avoided.
More serious issues arise when there are political or religious meaning attached to certain symbols. E.g., the symbol of “Swastika” is pretty much prohibited in many countries, because Nazis used it; however, it is the auspicious symbol of “Well Being” in Hinduism, Buddhism and Jainism and is reverently displayed on entrances to homes and temples in Nepal, India, Thailand, Mongolia, Sri Lanka, China and Japan. Similar issues arise when an image or icon resembles a religious symbol like the crescent of the moon, or the trident; these can start a backlash from religious factions or governments. In the current era of political and cultural correctness, it makes sense to avoid any images which may spur adverse reactions.
The images of flags of countries are not a big problem, as long as one sticks to the standard images similar to the ones used by payment gateways or web sites that show a drop down of flags to choose country (e.g. xe.com)
Extra care should be taken while displaying maps of countries due to the ever-changing border disputes between countries. One should use well known map providers (Google, Bing, MapBox etc.) and make sure to have a disclaimer (vetted by the legal folks) under the map, something like : “This map is for indicative purposes only and may not accurately depict the international borders”.
2.2 Colors
Though not a very big-ticket item, some colors have regional/cultural significances. A person in India will associate Orange (which is almost Saffron) with Hinduism, Blue with Buddhism, and Green with Islam, but in Ireland, Green is associated with Saint Patrick’s Day. Color red could mean a positive movement in stock markets in Japan, but it means a negative movement in USA.
This is more in the theming and branding realm, but one should be aware of overlaying symbols on colors, it might inadvertently mean something else. e.g. putting a X sign on the color of religious significance/ political party may be considered as a “Ban that religion / political party” message and interested activists may start threatening.
2.3 Text and Strings
2.3.1 Translation
Getting a native speaker of the language to translate or tweak machine translated text is the correct way to go. Machine translation services do a good job of translating but native speakers of the language can tweak the machine translated text to incorporate more apt phrases and the subtleties of the languages.
Never construct sentences in parts. Let us take an example: Online shopping site wants to show friendly messages.
Your basket contains one large yellow shirt.
Novice programmers will code the string as:
Your basket contains <QTY> <SIZE> <COLOR> <ITEM>
Replace QTY, SIZE, COLOR, ITEM at run time and add a small logic to use plural of the <ITEM> in case QTY is more than one, or put a “(s)” after the <ITEM> This will fly ok in English.
But in French, adjectives have a gender and singular/plural variants, and <SIZE> goes before and the <COLOR> goes after the <ITEM>
- Votre panier contient une grande chemise jaune.
If instead of one shirt it were one hat, it would be
- Votre panier contient un grand chapeau jaune.
In Hindi even the verbs have genders and change according to the subject.
The subject – object – verb positioning is different in different languages. In English verbs come after the subject: for example, the genderless English sentence “I had gone to Mumbai”, will become “मैं मुंबई गया था” (for a man) or “मैं मुंबई गयी थी” (for a woman), in Hindi; the appropriate form of the verb will be used depending upon the gender of the subject.
Therefore, one should translate the whole strings, never construct it in parts.
“Your basket contains <QTY> <SIZE> <COLOR> <ITEM>”
In French will be
“Your basket contains <QTY> <SIZE> <ITEM><COLOR>”
And in Hindi it will be
“आपकी टोकरी में <QTY> <SIZE> <COLOR> <ITEM> है”
However more code will be needed to pick the correct gender for <SIZE> and <COLOR> depending upon the gender of the <ITEM>. Instead, one can think about doing something like this:
- Your Basket – Item: <ITEM>, Quantity: <QTY>, Size: <SIZE>, Color: <COLOR>
And all languages may be satisfied.
English- Your Basket – Item: Shirt, Quantity: 1, Size: Large, Color: Yellow
French – Votre panier – Article : Chemise, Quantité : 1, Taille : Grand / Grande, Couleur : Jaune
Hindi – आपकी टोकरी – वस्तु : कमीज, संख्या: १, आकार : बडा / बडी, रंग: पीला/पीली
Etc.
But it is not as friendly as “Your basket contains one large yellow shirt” … This is a compromise for reducing localization costs and finally ends up being a business decision.
The cost of translation itself may be small but the cost of assuring its quality can be an expensive item and needs strict review by native speakers of the language.
2.3.2 Hardcoded Strings and Images
One should never hardcode any strings or even images that will be seen by the user. There are many ways to pick up the correct strings and images at run time. They could be in resource files or string tables loaded at run time by the rendering program. The program itself should be completely content agnostic and should be able to take any strings / images at run time.
All platforms have ways of picking up correct resources at run time. One can use them or invent one’s own ways but one should remember never to hardcode. Here are a few links to various platform documentation
https://developer.android.com/guide/topics/resources/localization
https://developer.apple.com/localization/
https://docs.oracle.com/javase/8/docs/technotes/guides/intl/index.html
https://learn.microsoft.com/en-us/dotnet/core/extensions/localization
and one can find specific details about recommended strategies for different technologies PHP, Python, React, Angular, etc. on respective web sites.
Ever friendly and informative WIKIPEDIA has this great article: https://en.wikipedia.org/wiki/Internationalization_and_localization